Common speech-to-text architectures, explained without the fog.
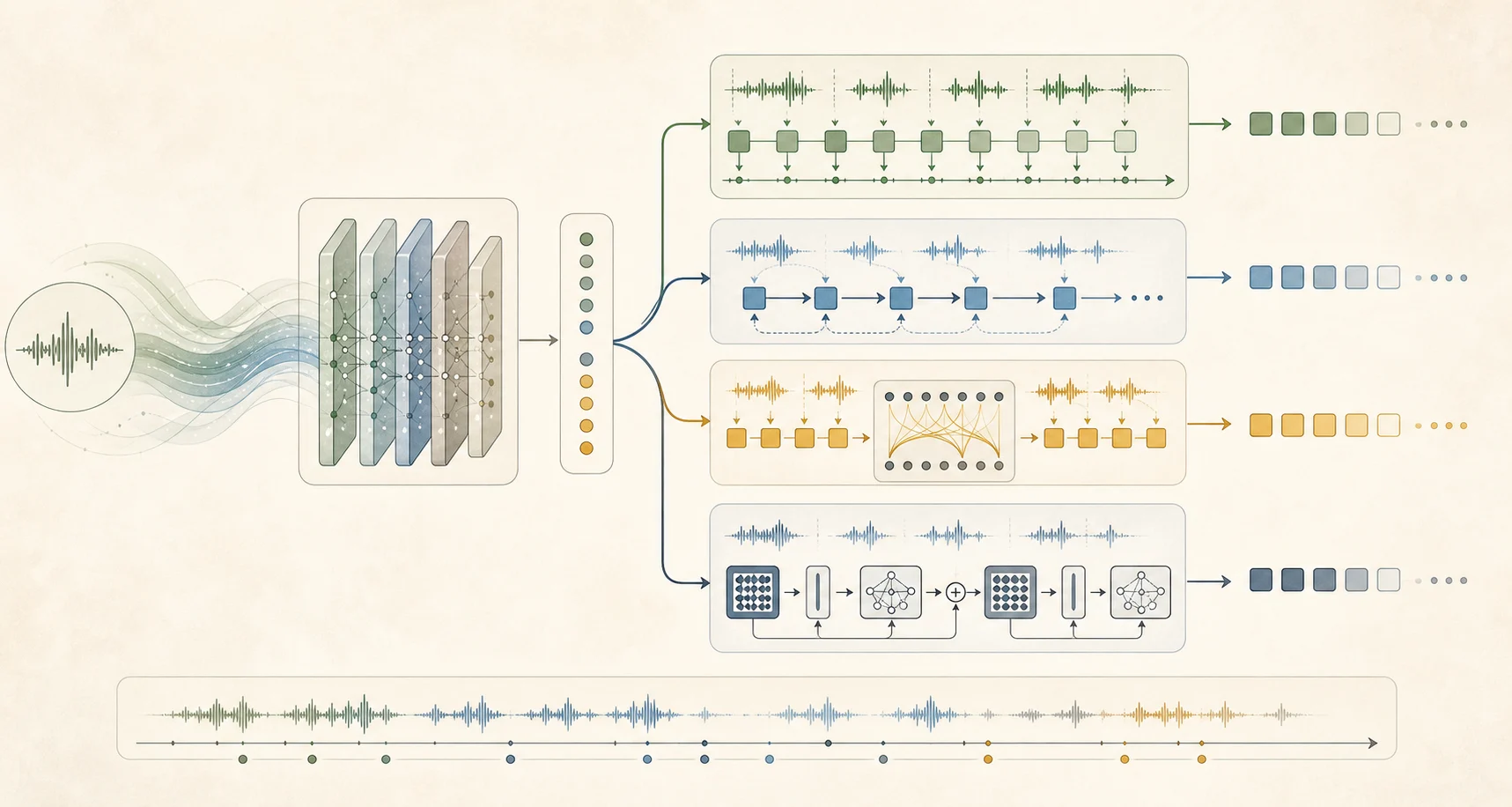
ASR is not one model shape. CTC, RNN-T, TDT, Conformer encoders, and encoder-decoder Transformers all make different bets about speed, streaming, alignment, and accuracy.
Speech-to-text looks simple from the outside: audio goes in, words come out. Under the hood, the architecture decides almost everything that users feel: latency, streaming behavior, punctuation quality, robustness to noise, and whether the model is pleasant to run locally.
Muesli cares about these details because local ASR is not a slogan. If transcription starts on your Mac, the model shape has to respect power, latency, memory, and the fact that people do not want to manage a research project before a meeting note appears.
What are the main ASR architecture families?
CTC
Learns a monotonic alignment between audio frames and output tokens. It is simple, fast, and useful when you want efficient transcription without an autoregressive decoder.
RNN-T / Transducer
Predicts tokens while audio streams in, combining an acoustic encoder with a prediction network and joint network. It is a classic choice for low-latency streaming ASR.
TDT
Token-and-duration transducer extends the transducer idea by predicting token duration, which can make efficient long-form or streaming transcription more practical.
Encoder-decoder Transformer
Encodes audio features, then decodes text autoregressively with attention. Whisper popularized this style for robust multilingual transcription.
Conformer
Combines convolution with self-attention so the model can capture both local acoustic patterns and longer context. Many modern ASR encoders use Conformer-style blocks.
Surrounding systems
VAD, diarization, punctuation, neural AEC, and post-processing are not ASR architectures, but they decide whether transcription works in real meetings.
When is CTC the right architecture for speech-to-text?
CTC is attractive when you want a direct audio-to-token path with a monotonic alignment. It does not need a separate autoregressive decoder to emit every token, which makes it simpler and often faster to run.
The tradeoff is that CTC can be less expressive than decoder-heavy systems. It is a strong building block, not a magic answer for every meeting, accent, language, or punctuation problem.
Why do RNN-T and TDT matter for streaming ASR?
Transducer models are built for the situation where audio is still arriving. Instead of waiting for the whole file, the model can emit text as speech continues. That is why RNN-T-style systems became common in live voice products.
TDT keeps the same broad streaming instinct but adds duration modeling. For local speech-to-text, this matters because streaming is not only about speed; it is also about doing useful work within memory and power limits.
How do common ASR architectures compare?
Why do modern ASR models use Conformer encoders?
Speech has local structure and long-range context. Convolution is good at local acoustic patterns; attention is good at broader context. Conformer combines both, which is why it shows up across modern ASR systems.
For Muesli, the practical lesson is simple: model architecture affects whether local inference feels instant or heavy. The best local model is not always the biggest model. It is the one whose architecture fits the job.
What makes encoder-decoder speech-to-text different?
Encoder-decoder systems turn audio features into an internal representation, then decode text with an autoregressive language-like decoder. Whisper is the reference point many people know: robust, multilingual, and easy to reason about as a sequence-to-sequence model.
The cost is latency. Autoregressive decoding can be slower than more direct approaches, especially on smaller devices or short dictation snippets where every extra second is noticeable.
What architecture is best for local speech-to-text on Mac?
There is no single winner. Short dictation wants speed. Meeting transcription wants robustness over longer audio. Streaming wants low latency. Multilingual transcription wants broader training data and decoding behavior.
That is why Muesli supports multiple local model paths instead of pretending one architecture is always right. The product bet is that speech-to-text should start locally when it can, and the model should fit the workflow rather than the other way around.
Where should I go next?
NVIDIA Parakeet speech-to-text
A practical model guide for Parakeet, TDT, CTC, and why it is interesting for fast local English ASR.
OpenAI Whisper speech-to-text
A model guide for Whisper, encoder-decoder ASR, multilingual transcription, and local inference tradeoffs.
Local speech-to-text glossary
Definitions for ASR, VAD, diarization, neural AEC, CoreML, and Apple Neural Engine.
Apple Neural Engine speech-to-text on Mac
Why local inference on Apple Silicon changes the economics and latency of speech-to-text.